なぜやったか
現在所属する企業ではWazuhを利用してサーバの不正検知を行っている。以前ITメディアさんに取材頂いた記事は下記です。

現在はWazuhのアラートをSlackチャンネルに投稿しているのだが、デプロイ時など大量のファイル変更がある場合や、IaCのアプライ時にノイジーなアラートがあり、見逃しのリスクがある。それを解決するためにmimizukuというライブラリを開発して、機械学習を用いて作成したモデルで異常検知できるようにした。

またmimizukuという名前はAIがいい感じに出してくれなかったから、あんちぽさんが一生懸命考えてくれた。

実装概要
Local Outlier Factorという教師なし学習の手法を利用しています。超簡単に述べると、学習データと比較して、推論したい値が外れ値となるようなものを検知できるようにしています。例えば普段変更されないようなファイルがサーバに追加されたとか、普段実行されないようなコマンドが実行されたとかそういうものです。イメージとしては下記のような感じです。
import matplotlib.pyplot as plt
import numpy as np
from sklearn.neighbors import LocalOutlierFactor
# テストデータの生成
np.random.seed(42)
# 正常なデータポイントを2次元の正規分布から生成
X_inliers = 0.3 * np.random.randn(100, 2)
X_inliers = np.r_[X_inliers + 2, X_inliers - 2]
# 異常なデータポイントを生成
X_outliers = np.random.uniform(low=-4, high=4, size=(20, 2))
# データセットの結合
X = np.r_[X_inliers, X_outliers]
# LOFによる異常検出
clf = LocalOutlierFactor(n_neighbors=20, contamination=0.1)
y_pred = clf.fit_predict(X)
# 異常度のスコア(negative_outlier_factor)は負の値が大きいほど異常
outlier_scores = clf.negative_outlier_factor_
# グラフの描画
plt.title("LOF (Local Outlier Factor)")
plt.scatter(X[:, 0], X[:, 1], color="b", label="Inliers")
# 異常値のみ赤で表示
radius = (outlier_scores.max() - outlier_scores) / (
outlier_scores.max() - outlier_scores.min()
)
outliers = y_pred == -1
plt.scatter(
X[outliers, 0],
X[outliers, 1],
s=1000 * radius[outliers],
edgecolors="r",
facecolors="none",
label="Outliers",
)
plt.legend()
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()
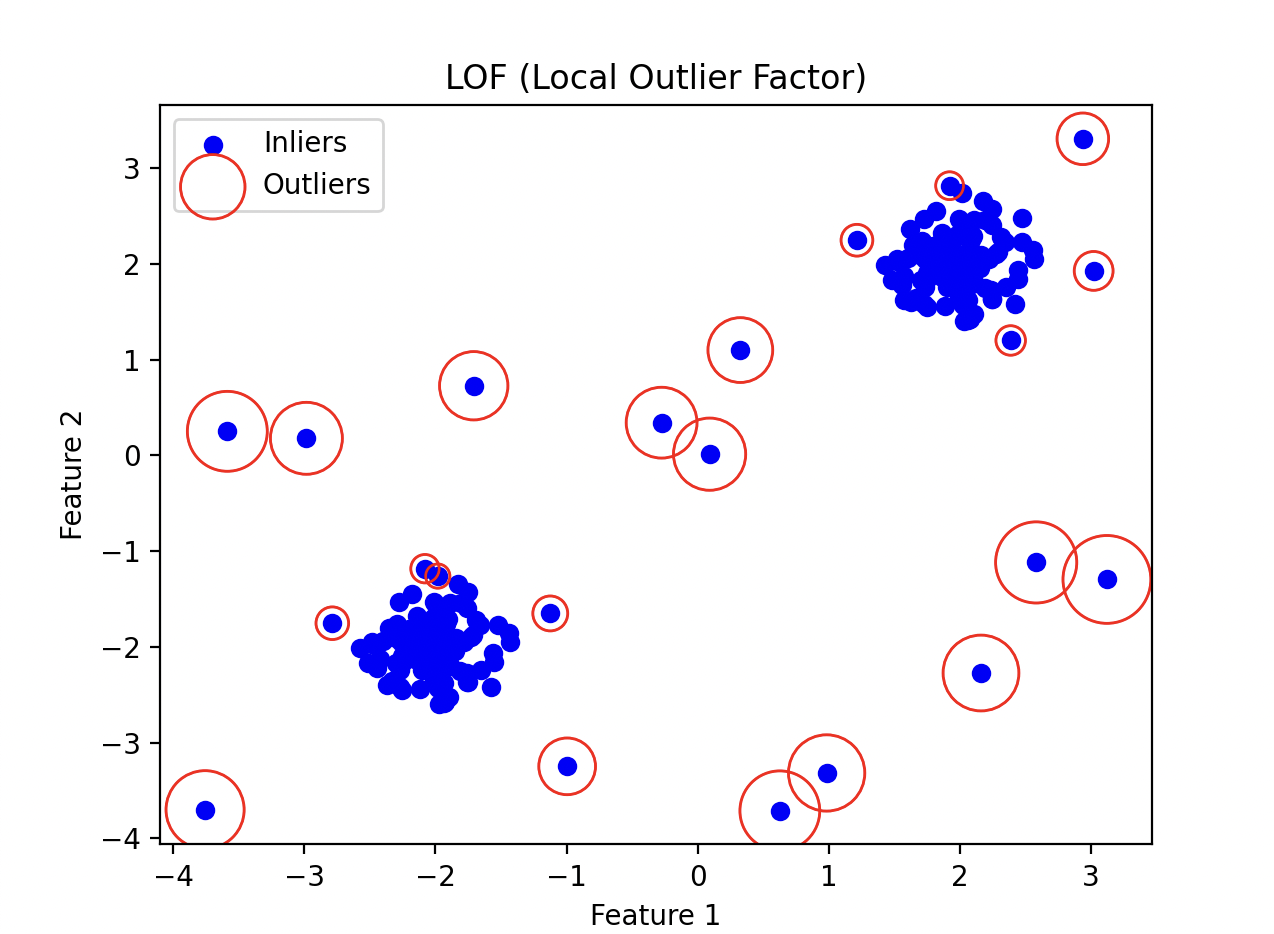
上記のコードを実行すると下記のグラフが出力されます。

この赤丸の箇所が、異常として検知された値です。集団から外れた点に丸がついているのが確認できると思います。
ただし、教師なし学習なので、学習データにどのくらい異常が含まれているのかを指定するパラメーターや、学習するデータ量でかなり精度が異なりますが、手元での検証では、例えば su - oreha-kaizoku-oh-ni-naru とか実行すると検知されますし、 /home/pyama/yabai-file などを作成しても検知されます。
使い方
READMEにも記載がありますが、下記のように学習できます。
import pandas as pd
from mimizuku import Mimizuku
# Initialize the model with custom settings
model = Mimizuku(contamination=0.001, n_neighbors=5)
# Train the model using a Wazuh alert log file or DataFrame
model.fit("./training.json")
# Save the trained model for later use
model.save_model("./models")
そして学習したモデルを利用するには下記のように実行できます。
import pandas as pd
from mimizuku import Mimizuku
# Load a saved model, ignoring specific users
loaded_model = Mimizuku.load_model("./models", ignore_users=["root"])
# Use the loaded model to detect anomalies in a new Wazuh alert log file
anomalies_df = loaded_model.predict("./test.json")
# Display the detected anomalies
print("Detected anomalies:")
print(anomalies_df)
上記では推論するのにファイルを渡していますが、pandasのDataFrameをそのまま渡すことも出来ます。私の会社の環境ではWazuhのアラートをkafkaに入れて、それを順次読み込んで、異常検知したらSlack通知するような使い方をしています。
最後に
もともとSREやバックエンドエンジニアとしての経験を持つ僕が機械学習をスイスイ最近やっているのは、間違いなくLLMの支援による能力の延伸が大きいです。
以前、深層学習についてはゼロから作るDeep Learningを始め、離散数学とかを読み漁り体系的に学習していたのがあったのですが、なかなか自分であれこれ作るには至りませんでした。しかし、ChatGPTをはじめとしたLLM技術によって自分の知識を組み合わせるだけでどんどん実装が進むようになり、今回紹介したようなものを簡単に作れるようになったと感じています。今後もLLM活用してどんどん自分の適用範囲を広げていきたい。
ただ、機械学習自体は、本番データ学習して、本番で試してみたいなイテレーションが普段の開発よりだいぶ時間かかるので自身の働き方とミスマッチする部分はあって、複数タスク持ってないと暇になるなぁってのは感じた。
機械学習完全に理解したので、何でも聞いて下さい。(うs